Be Curious About Your Compute
After facing a blocker related to hardware, I decided to deep dive into it: An Explainer

Hardware Often Takes The Backseat
I've been a software guy throughout my journey and rarely I've tried to lift the curtain up and focus on the hardware. Those rare times probably happened during my IOT study sessions at my engineering course.
Most of the blockers I've ever faced during my AI engineering journey, have been related to software. Broken drivers, unpatched source code, outdated libraries and of course classic python quirks.
But one day I faced a blocker, obviously not knowing that it was hardware related. At my internship, I was trying to draw inference from an Automatic1111 server on AWS, the server was equipped with two specific diffusion models, one was SDXL (very heavy) another was an SD1.5 (lighter). However drawing inference from one model caused the next inference from the second model to be very slow. My first reaction was that it was because of caching.
But after debugging this issue, I learned that this was expected behavior by Automatic1111 module. It loaded a model into VRAM and "kept it hot" for fast inference then loaded the second model, hence resulting in slow inference.

That day I learnt that understanding and knowing the relation between the software and hardware interactions goes a long way.
"Not thinking about the hardware" is something I observe a lot from peers and engineers. So, I had the idea to write this blog.
Types Of Available Hardware
CPU vs GPU vs TPU
| Aspect | CPU | GPU | TPU |
|---|---|---|---|
| Role | General-purpose processor, brain of the computer | Originally for graphics, now massively parallel compute | Custom ASIC by Google for tensor operations & deep learning |
| Cores | Few powerful cores (2–64, more in servers) | Thousands of lightweight cores (A100 ~7,000+) | Systolic arrays with Matrix Multiply Units (MXUs) |
| Execution Model | Low-latency, sequential, strong branch handling | SIMT/SIMD, warp scheduling, high throughput | Data flows across systolic array; highly specialized instructions |
| Memory | Large cache hierarchy, moderate bandwidth | High-bandwidth VRAM (HBM/GDDR), smaller caches, bulk data optimized | HBM tightly coupled with compute; optimized for DL precision formats |
| Strengths | Versatile, single-thread performance, task switching | Matrix/vector math, AI/ML training, rendering, high throughput | Extremely efficient at AI training/inference, high perf-per-watt |
| Weaknesses | Limited parallelism, not efficient for massive matrix ops | Poor at branch-heavy sequential code, higher latency, needs CUDA/OpenCL | Not general-purpose, tied to Google ecosystem, less flexible |
AI or any computationally expensive workload, requires extremely high throughput as the calculations are extremely straight forward (matmul, gradient averages, dot products, etc...) unlike the calculations the CPU does which includes complex branching logic and minimal latency. Hence GPUs and TPUs are extremely popular choices.
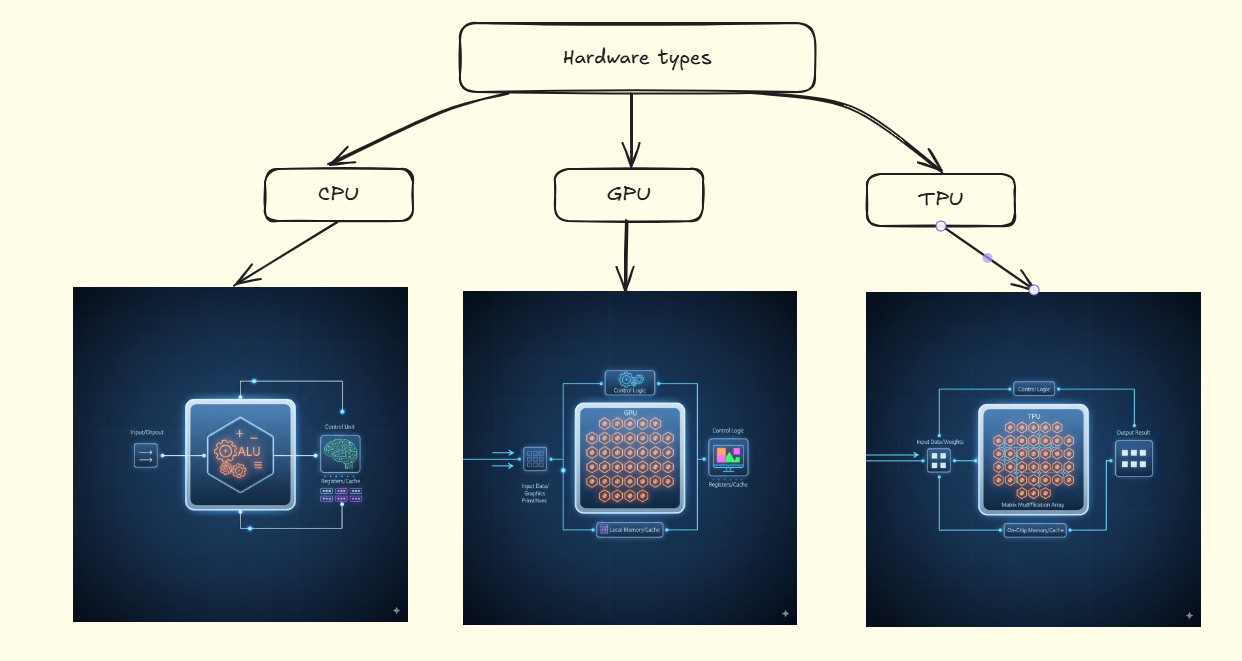
GPUs, in particular, have extremely high bandwidths but unlike TPUs, they interface well using CUDA lib and Pytorch or TensorFlow also include high interoperability with them.
Bottlenecks
It is normal to focus on metrics like TFLOPs. But a systems performance and turnaround time is often limited by how quickly data moves and can be accessed, not just how fast can it be processed.
-
Memory capacity (VRAM) and bandwidth are frequently more important than raw compute power. A processor is inefficient if it sits idle waiting for data. VRAM capacity is a key constraint, as it determines whether a large model, such as an LLM, can fit onto a single GPU. For instance, a high-TFLOP consumer GPU like an RTX 4090 with 24 GB of VRAM cannot train models that require the 80 GB or more offered by datacenter GPUs. VRAM size also limits the training batch size, affecting efficiency.
-
When scaling to multiple GPUs for larger models, the interconnect, the communication pathway between GPUs could become the main bottleneck. Standard interconnects like PCIe have limited bandwidth (around 64 GB/s), which can get saturated when GPUs synchronize data, leading to diminishing returns when scaling beyond a few GPUs. In contrast, proprietary technologies like NVIDIA’s NVLink provide vastly superior bandwidth (up to 900 GB/s), resulting in efficient scaling for training massive foundation models.
-
The entire system can be constrained by slow data I/O from storage. If data cannot be loaded from disks to the GPUs quickly enough, even the most powerful hardware will be wasted, creating a foundational bottleneck.
Accelerators
Modern AI accelerators are designed around specific philosophies and each type of accelerator handle different types of workloads.
- NVIDIA H100 focuses on cutting-edge training with its Transformer Engine and FP8 support, demanding extreme bandwidth and power efficiency for massive LLMs.
- Google TPU v5p uses a systolic array (MXU) for extreme efficiency in large-scale, matrix-heavy workloads, tightly coupled with Google’s distributed infrastructure.
- AMD MI300 competes by integrating CPU and GPU components into one package, offering a large unified memory pool — attractive for diverse HPC and AI workloads where flexibility and capacity matter.
These differences reflect the architectural trade-offs between general-purpose flexibility (GPU) and specialized efficiency (TPU), with AMD carving a hybrid path.
Accelerator Comparison
| Accelerator | Memory | Bandwidth | Key Use Case |
|---|---|---|---|
| NVIDIA H100 | 80 GB HBM3 | ~3.0 TB/s | Cutting-edge LLM training, HPC workloads with extreme throughput needs |
| AMD MI300X | 192 GB HBM3 | ~5.3 TB/s | Large-scale AI training, HPC, and very large models (fits datasets in memory) |
| Google TPU v5p | 95 GB HBM2e per chip | ~2.77 TB/s | Large-scale AI training/inference; matrix-heavy workloads in Google ecosystem |
Practical Tips
To optimize AI workloads we need to focus on data movement too not just compute speed.
- Profile your system: The first step is to identify where the bottlenecks are. Is it memory capacity (VRAM), memory bandwidth, interconnect speed between GPUs, or slow data loading from storage?
- Use mixed precision (AMP): Modern GPUs have specialized Tensor Cores that accelerate FP16/BF16 computations. Using Automatic Mixed Precision (AMP) in frameworks like Pytorch significantly speeds up training by using lower precision for matrix maths while maintaining accuracy with FP32 for sensitive operations like loss calculation. This also reduces VRAM usage.
- Tune batch size and data loaders: VRAM capacity limits your batch size. A larger batch can improve hardware utilization, but a small one may be forced by memory constraints. Ensure your data loading pipeline from storage to GPU is not the bottleneck, as even the fastest GPU is wasted if it's waiting for data.
- Leverage optimized frameworks: For multi-GPU training, use libraries like PyTorch's
DistributedDataParallelwith NCCL backends, or advanced frameworks like DeepSpeed, to efficiently manage gradient synchronization, which is often a key bottleneck. These tools are crucial for scaling effectively.
Conclusion
You don't need to be a GPU engineer or a chip designer to understand the nuances of hardware and the interaction between hardware and software. Only requirements are to keep the hardware in mind while designing systems and to Be Curious About Your Compute